

The Best AI Models of May 2026
Claude Opus 4.8 has joined GPT-5.5 at the top — and the smartest move now is learning when to use each.

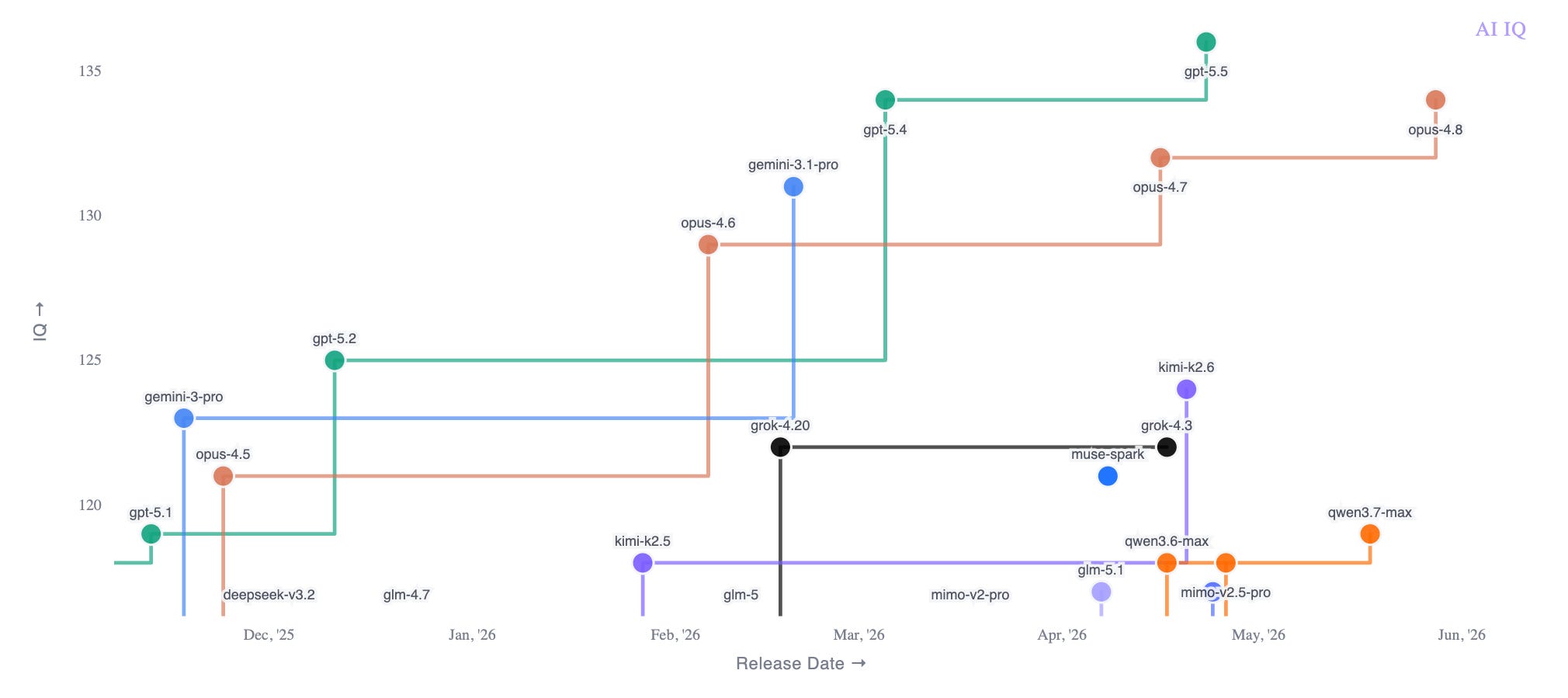
May was the month Claude Opus 4.8 joined GPT-5.5 at the top of the AI model landscape.
GPT-5.5 still has the strongest claim to the top composite spot on AI IQ. But Opus 4.8 now wins enough important categories — especially writing, design, frontend engineering, desktop navigation, and hallucination resistance — that treating GPT-5.5 as the sole leader misses what changed in May.
The interesting thing is that the frontier has become more textured than that. Opus 4.8 and GPT-5.5 are both #1-caliber models, but they are #1 in different ways.
GPT-5.5 looks stronger at math and science, terminal use, backend engineering, and instruction following.
Claude Opus 4.8 looks stronger at writing, design, desktop navigation, frontend engineering, and resistance to hallucination.
At the broadest level, I would call reasoning and coding basically tied. But “reasoning” and “coding” are now too broad to be especially useful. The important action is happening underneath those labels.
The practical lesson is this:
Using only one of these models all the time is leaving intelligence on the table.
The best AI users and teams are increasingly going to act less like fans of one model family and more like portfolio managers of intelligence. They will use GPT-5.5 when GPT-5.5 is the right tool. They will use Opus 4.8 when Opus 4.8 is the right tool. And when the task does not require maximum frontier intelligence, they will pull in models like Gemini 3.1 Pro, Grok 4.3, Kimi K2.6, and DeepSeek v4 Flash to get better intelligence per dollar.
That is the state of AI models in May 2026.
The frontier is not a single winner anymore.
It is a map.
The benchmark-card era is not enough anymore
Every major model launch now comes with a benchmark card.
The lab announces the model. The card highlights the scores where the new model looks strong. The obvious comparison points are included. The less flattering or less convenient comparisons are often missing.
That does not mean the cards are useless. They are often full of real information.
But they are incomplete by design.
They are launch materials, not complete maps of the model landscape.
That matters more now because the frontier models are no longer separated by huge, obvious gaps. When one model dominates across the board, a simple benchmark card can be good enough. But when models are trading wins across coding, reasoning, agentic work, instruction following, reliability, cost, and style, the old “which one has the biggest number?” approach starts to break.
May made that very clear.
Claude Opus 4.8 launched and immediately became one of the most important models in the world. GPT-5.5 already had the strongest claim to the overall top spot on AI IQ. Gemini 3.1 Pro remained extremely competitive, especially when cost is part of the conversation. Grok 4.3 produced one of the most surprising benchmark wins of the whole comparison. May also brought Qwen3.7-Max, another notable release in a month where the frontier kept getting more crowded and more interesting.
But the central story is Opus 4.8 joining GPT-5.5 at the top.
And the deeper story is that “best model” is no longer a one-dimensional question.
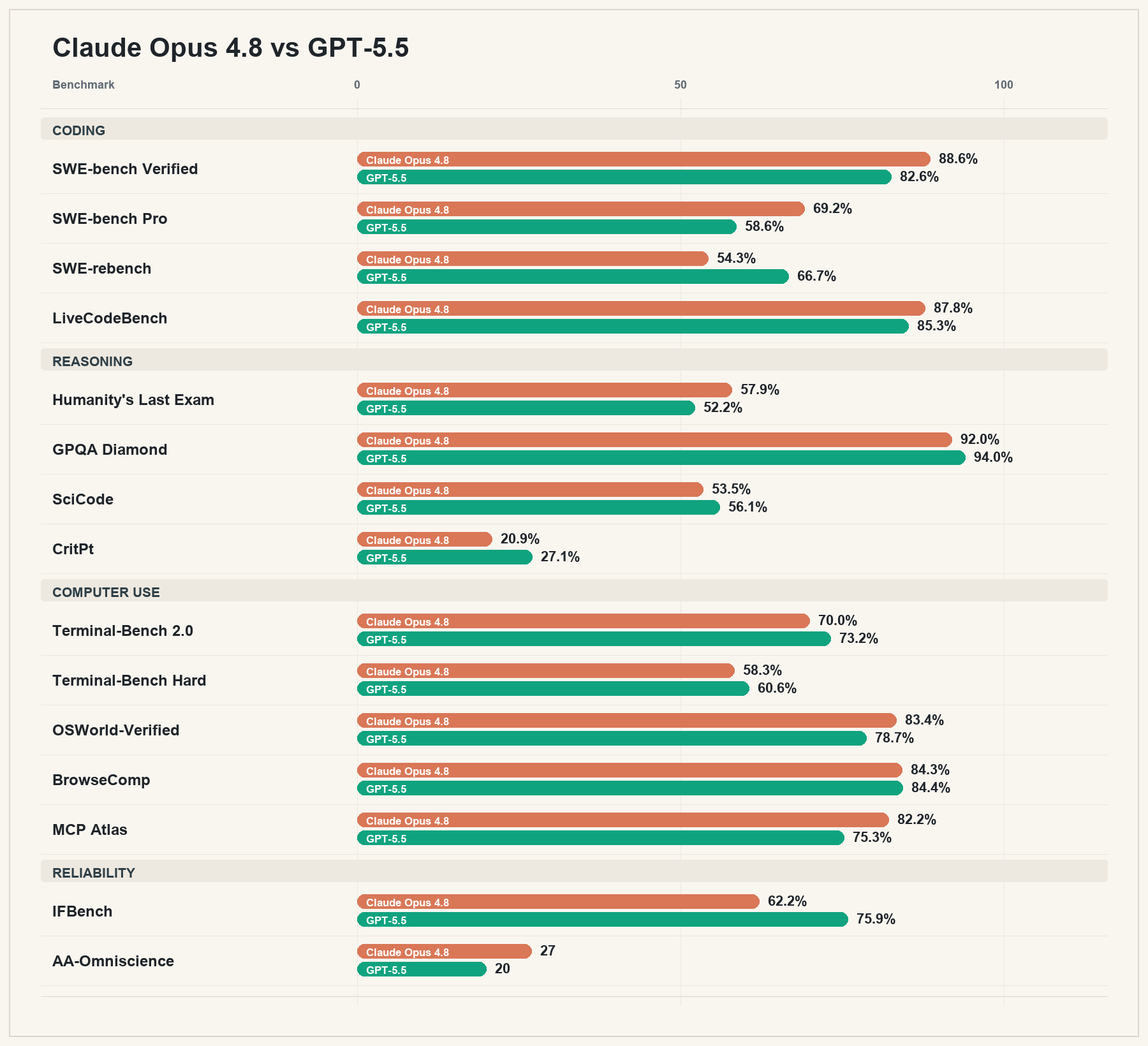
Opus 4.8 vs GPT-5.5: co-leaders, not clones
The easiest mistake is to ask whether Opus 4.8 is better than GPT-5.5.
That question is too blunt.
Opus 4.8 is better on some things. GPT-5.5 is better on others. Both are extraordinary. Both are state-of-the-art. Both are models you can use for serious work. And both will leave performance on the table if you use them blindly for every task.
On the benchmark set I pulled together, Opus 4.8 has major wins in areas like SWE-bench Pro, OSWorld-Verified, MCP Atlas, and AA-Omniscience. Those results line up with a broader impression: Opus 4.8 is extremely good when you want judgment, taste, carefulness, writing quality, frontend work, and GUI-style desktop navigation.
GPT-5.5 has major wins in areas like SWE-rebench, GPQA Diamond, SciCode, CritPt, Terminal-Bench, BrowseComp, and IFBench. That lines up with its own profile: GPT-5.5 is extremely good when you want math, science, terminal use, backend engineering, and precise instruction following.
The wrong conclusion is “Claude wins” or “GPT wins.”
The right conclusion is that the model landscape now has two co-leaders with different shapes.
That is a much more useful picture.
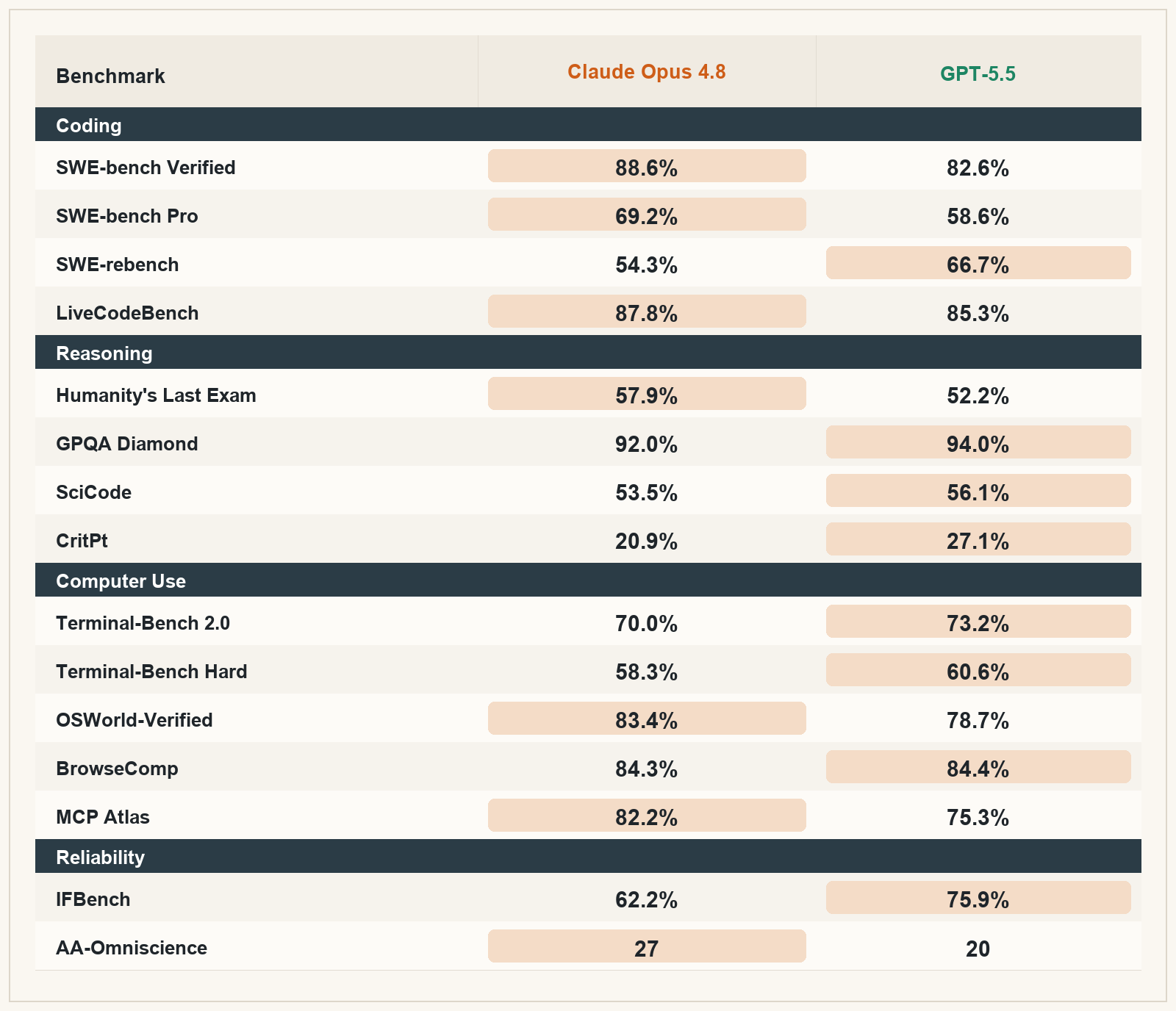
The best models of May 2026, by use case
Here is how I would think about model selection right now:

That table is deliberately practical.
Most people do not wake up wondering which model has the most elegant aggregate benchmark profile. They wake up wanting to build something, debug something, write something, analyze something, research something, automate something, or get something done.
For that kind of user, the right question is not:
“What is the best model?”
The right question is:
“What am I trying to do?”
Then you pick the model whose strengths match the job.
For my own work, I would reach for GPT-5.5 first for math, science, backend-heavy engineering, terminal-heavy workflows, and tasks where I want very tight instruction following.
Meanwhile, I would reach for Claude Opus 4.8 first for writing, design, frontend engineering, desktop navigation, product taste, and work where hallucination resistance and judgment matter more than raw technical aggression.
And when cost matters, I would start pulling Gemini, Grok, Kimi, and DeepSeek into the rotation.
That last point matters more than it may seem.
The four-model picture is even more interesting
Once you add Gemini 3.1 Pro and Grok 4.3, the story gets more complicated in a useful way.
Claude Opus 4.8 and GPT-5.5 are the central co-leaders. But Gemini and Grok are not just background characters.
Gemini 3.1 Pro remains one of the most important models in the ecosystem because it is strong enough to compete on serious reasoning and reliability benchmarks while also sitting in a much more attractive cost-performance region. It is the model I would pay especially close attention to if I were trying to maximize intelligence per dollar rather than chase the absolute top score.
Grok 4.3 is also more interesting than a simple composite ranking makes it look. Its IFBench result was one of the most surprising findings in this comparison. Instruction following is not a decorative trait. It is one of the core traits that determines whether a model is useful in real workflows.
A model that follows instructions well can be easier to route, easier to automate, easier to constrain, and easier to trust inside a repeatable system.
That is why the four-model view matters. It shows that the landscape is not just a ranking of overall intelligence. It is a set of different capability profiles, and those profiles become much more useful once you start thinking in terms of model rotation.
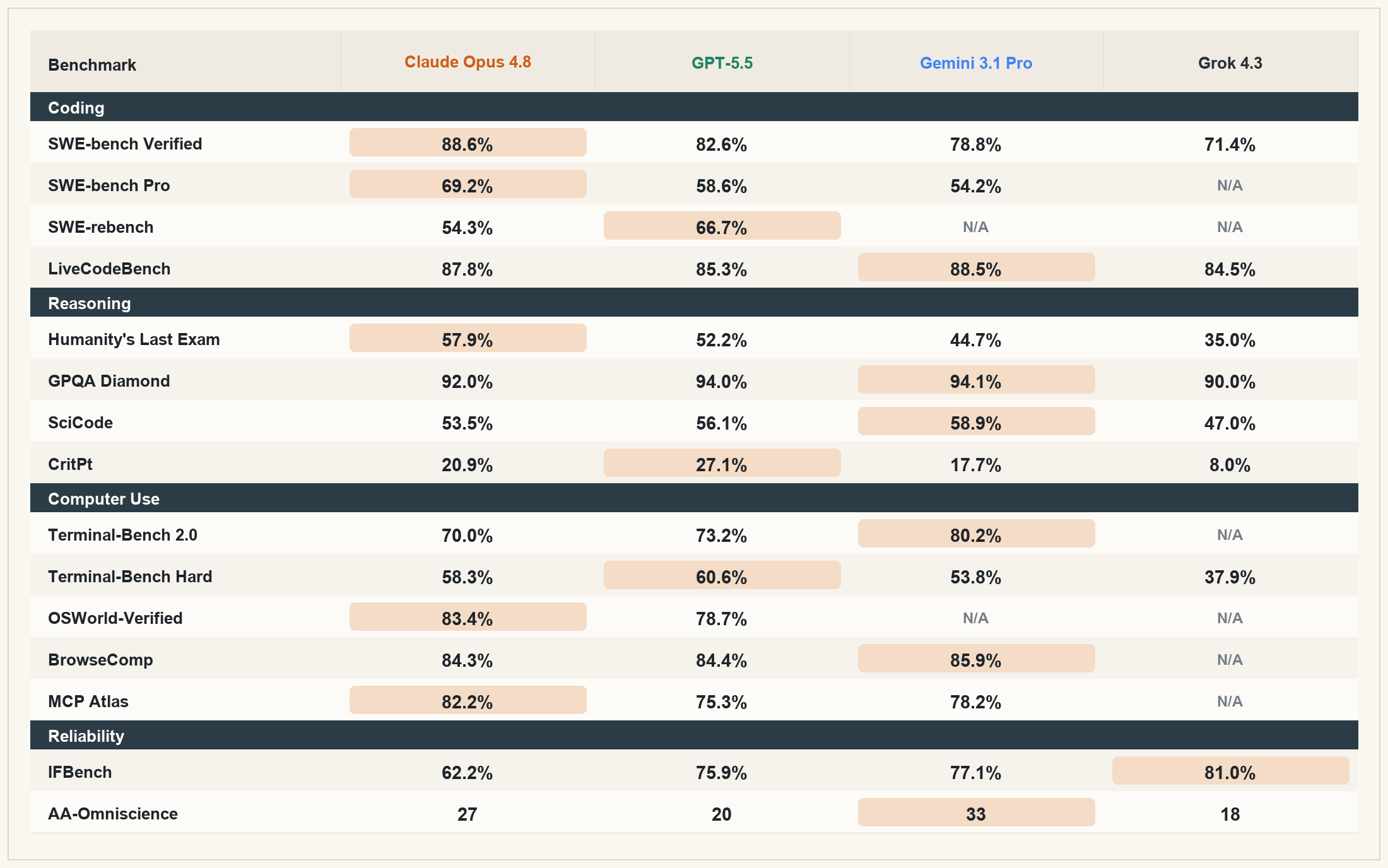
Reasoning is not one thing
The word “reasoning” gets used as if it describes one clean capability, but the May results show a more useful picture: GPT-5.5, Claude Opus 4.8, and Gemini 3.1 Pro are all fantastic reasoning models.
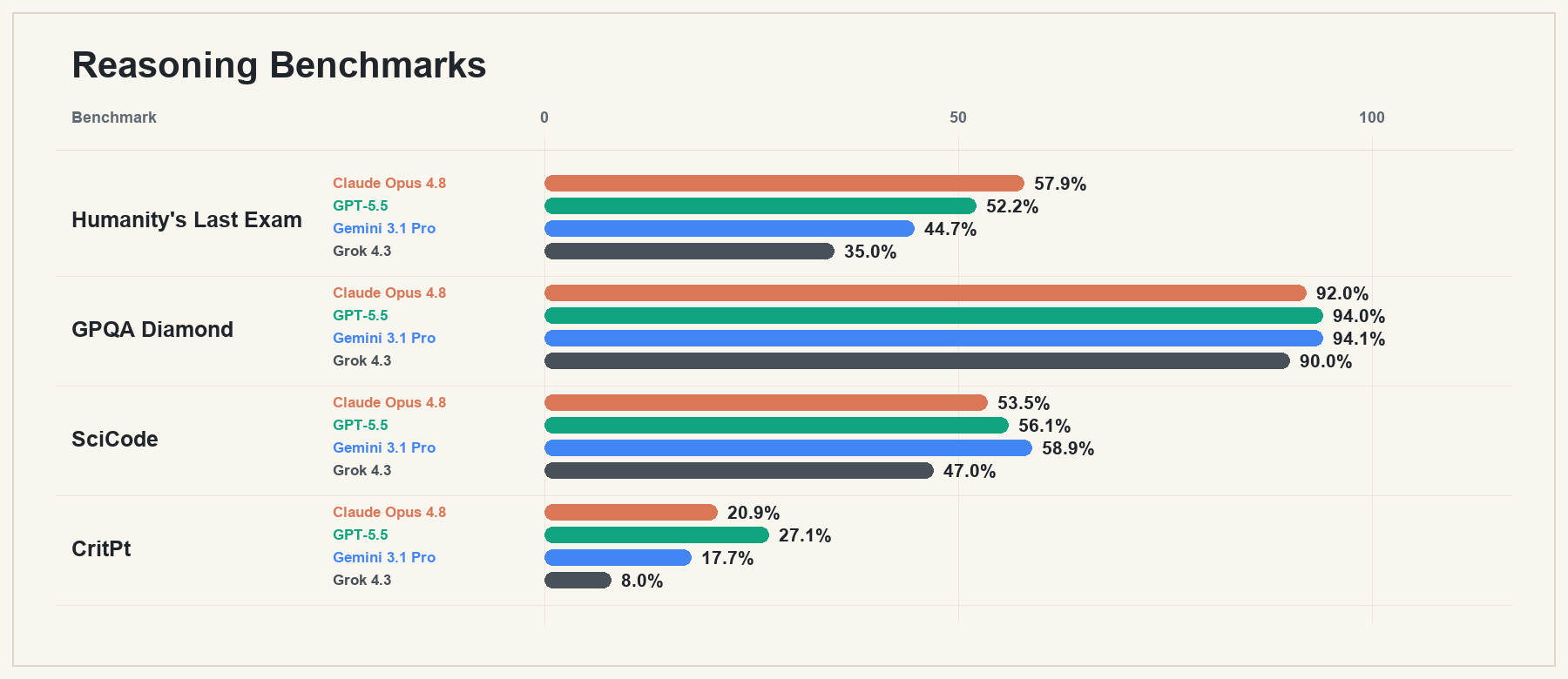
There are still meaningful differences. Gemini 3.1 Pro and GPT-5.5 have the strongest claim on the scientific reasoning slice of this comparison, while Opus 4.8 remains highly competitive and adds a win on Humanity’s Last Exam. The important point is not that one model owns reasoning. It is that the top tier now gives users a real pool of excellent reasoning options.
That is why broad model rankings are useful, but not sufficient. When people ask “which model is best at reasoning?” they are usually compressing too much into one word. Do they mean scientific reasoning, physics reasoning, long-form exam performance, code-adjacent reasoning, mathematical reasoning, or long-horizon planning?
The answer can change depending on which kind of reasoning they mean. The more frontier models converge overall, the more these subcategories matter.
Coding is not one thing either
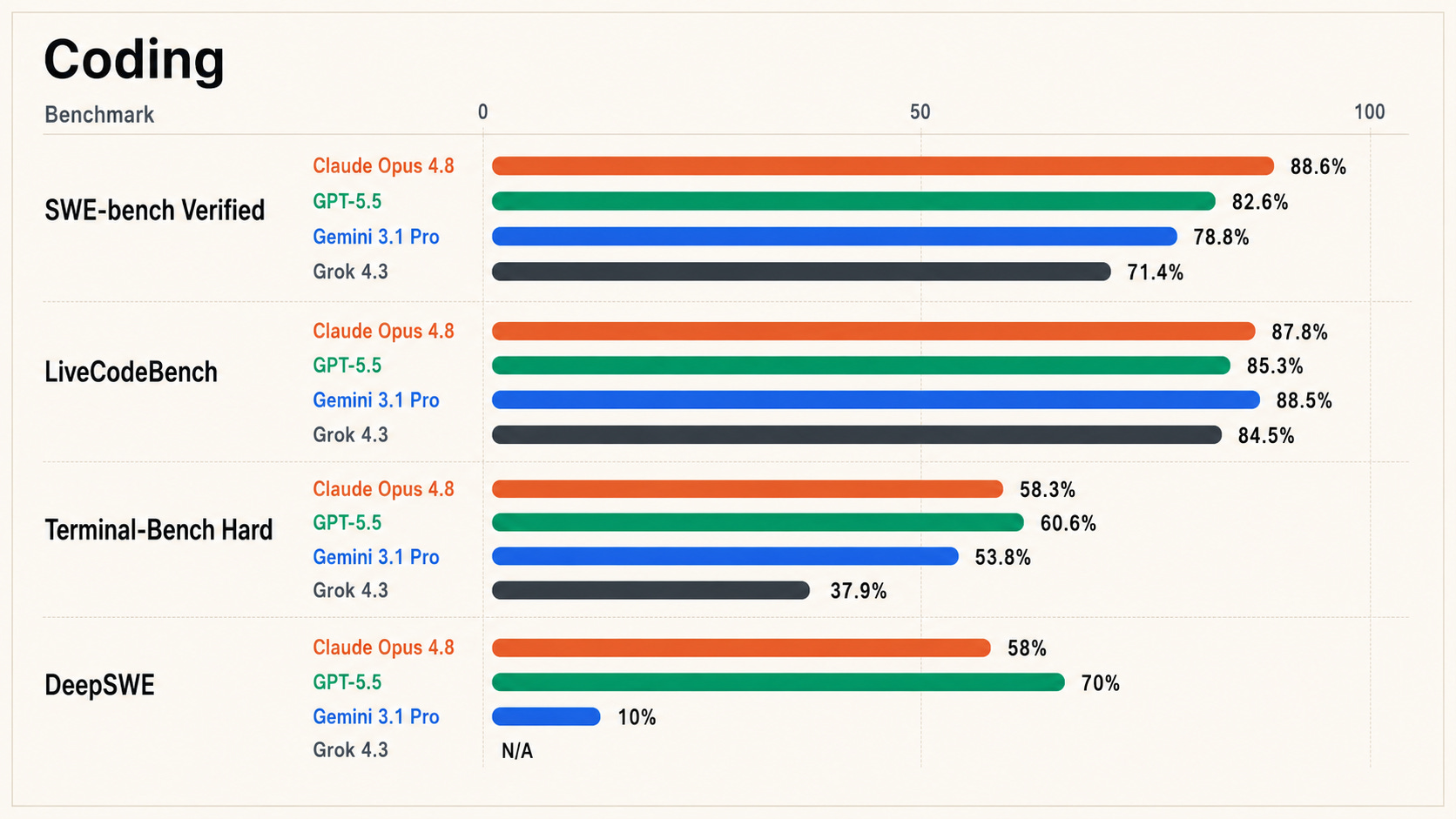
The same is true for coding. “Best coding model” sounds useful, but it hides too much. Coding includes backend engineering, frontend engineering, terminal use, bug fixing, repo navigation, algorithmic problem solving, refactoring, product implementation, UI taste, and long-running agentic work across messy codebases.
That is why I see GPT-5.5 and Opus 4.8 as effectively tied in coding overall, even though I would not use them identically. GPT-5.5 is the model I would favor for backend engineering, terminal-heavy workflows, systems-oriented implementation, and cases where the model needs to follow a precise technical plan. Claude Opus 4.8 is the model I would favor for frontend engineering, design-sensitive implementation, product polish, and work where writing quality, taste, and user experience need to come together with technical execution.
This distinction matters because “working code” is not always the same as “good software.” Some tasks reward raw implementation power. Others reward taste, interface judgment, maintainability, and the ability to produce something a human actually wants to use. The best coding model depends on which kind of coding you are doing.
Reliability is becoming a first-class capability
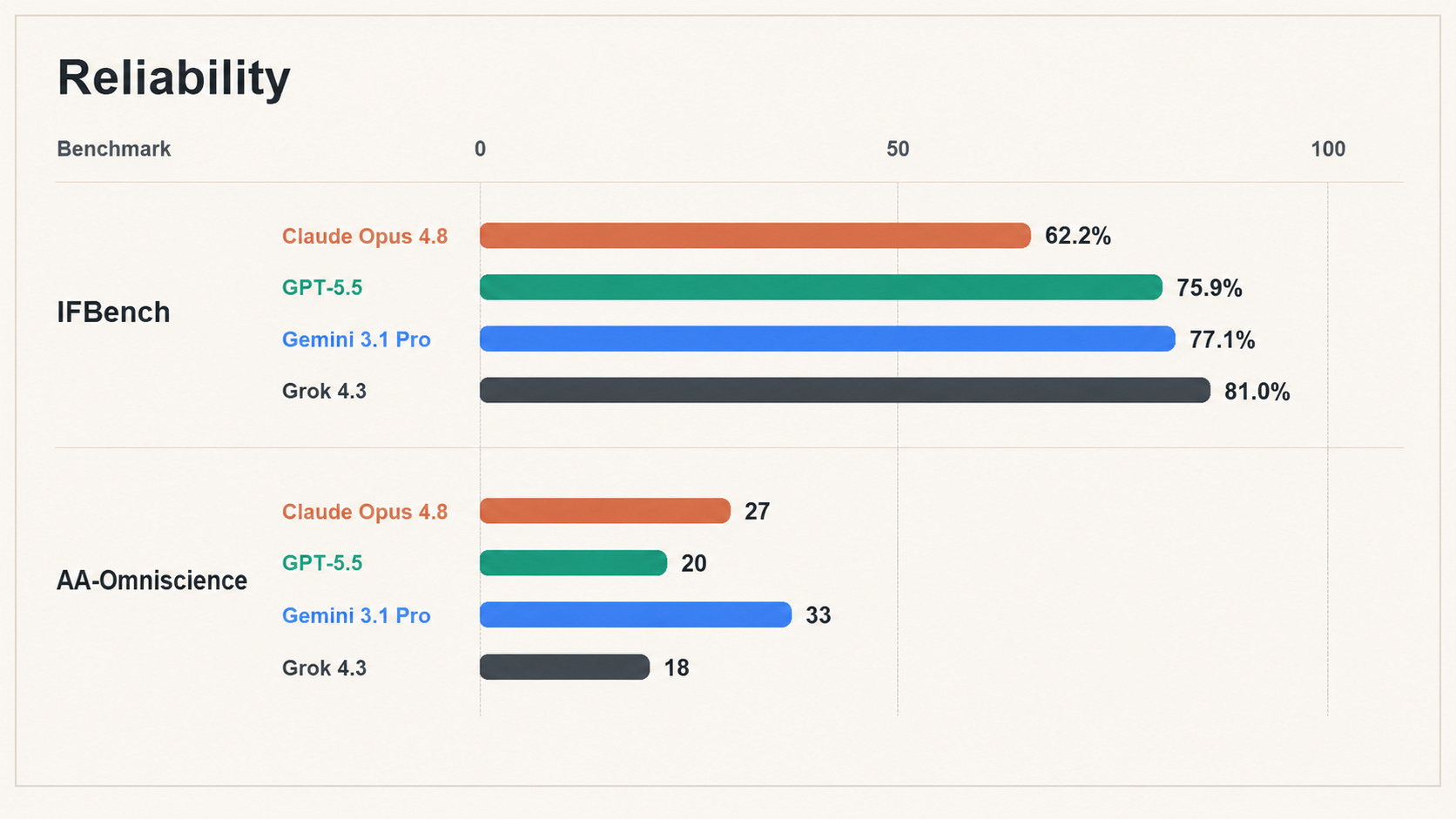
Reliability is not the boring part of model evaluation. It is one of the places where model differences become most operationally important.
A model that can solve hard problems but does not follow instructions cleanly is harder to automate. A model that is brilliant but overconfident is harder to trust. A model that looks impressive in demos but drifts in long workflows is harder to build around. This is why reliability benchmarks deserve more attention than they usually get.
Two results stood out in May: Grok 4.3 topping IFBench and Gemini 3.1 Pro topping AA-Omniscience. IFBench matters because instruction following is the foundation of almost every repeatable AI workflow. AA-Omniscience matters because hallucination resistance determines whether a model can stay useful when the answer is uncertain, obscure, or not actually knowable from context.
These results make the four-model picture more useful. GPT-5.5 and Opus 4.8 remain the co-leaders overall, but Gemini and Grok each show up strongly on traits that matter in production: knowing when not to guess, and doing exactly what the user asked. That is the kind of model intelligence that does not always dominate a composite leaderboard, but can make a huge difference in practice.
Cost matters because agents change the math
For a single high-stakes question, it often makes sense to use the strongest model available. If the task is important enough, pay for maximum intelligence.
But agentic workflows change the economics. Once engineers and organizations start running many agents for many tasks over long periods of time, token spend becomes an allocation problem. The question is no longer just “What is the smartest model?” It becomes “How much useful intelligence can I buy for this budget?”
That can point in two directions. Some teams want to reduce token spend while preserving as much capability as possible. Others are willing to spend the same amount, but want more total work done: more agents, more attempts, more critiques, more parallel exploration. In both cases, intelligence per unit cost becomes part of the routing decision.
This is where Gemini 3.1 Pro, Grok 4.3, Kimi K2.6, and DeepSeek v4 Flash become especially relevant. Not every task deserves the most expensive frontier model at the highest reasoning level. Sometimes the right move is GPT-5.5 or Opus 4.8 at full strength. Sometimes it is the same model at a lower reasoning level. Sometimes it is a cheaper model that gets you most of the way there for a fraction of the cost.
That is why the IQ vs. effective cost view on AI IQ matters. It does not just ask which model is smartest. It asks which models sit in the most useful region of the cost-performance landscape.
The next serious advantage is not just access to the best model. It is knowing how to allocate intelligence.
What AI IQ is trying to do
There is no single correct way to rate AI models. The best we can do is use the strongest available benchmarks, combine them carefully, and keep improving the map as the models and evaluations get better.
That is what AI IQ is for.
The IQ score is not meant to be the final word on a model. It is meant to create a better starting point: a common frame for comparing models across time, tracking the frontier, seeing which providers are moving fastest, and putting intelligence and cost on the same map.
That matters because the model ecosystem is getting too complex for launch cards and vibes. A single model can be excellent overall and still be the wrong choice for a specific workflow. Another model can sit lower on the composite leaderboard and still be the right choice when cost, instruction following, hallucination resistance, speed, or style matters more.
The ambition for AI IQ is to become more than a leaderboard. It should be a routing map, a buying guide, and a community intelligence layer for the model ecosystem: a way to understand which models are smartest, which are worth paying for, and which ones to use for the job in front of you.
That is where this gets exciting. The goal is not just to watch the frontier move. It is to help people use it better.
My current read on May 2026
Here is the compact version:
GPT-5.5 and Claude Opus 4.8 are the two top-tier defaults. GPT-5.5 still has the strongest claim to the top composite spot on AI IQ, with excellent breadth and particular strength in math, science, backend engineering, terminal-heavy work, and instruction following. Opus 4.8 has earned co-leader status with meaningful advantages in writing, design, frontend engineering, desktop navigation, and hallucination resistance.
Gemini 3.1 Pro is the cost-effective high-intelligence model to watch. It is strong enough to compete seriously on hard reasoning and reliability benchmarks, while sitting in a much more attractive cost-performance region than the most expensive frontier models.
Grok 4.3 is more useful than its broad ranking suggests. Its IFBench result is a reminder that specific capabilities can matter more than aggregate rank when you are routing models for real workflows.
Kimi K2.6 and DeepSeek v4 Flash belong in the cost-conscious agent rotation. When you care about high-volume work, parallel agents, and intelligence per dollar, they become part of the practical landscape.
Qwen3.7-Max was another notable May release. The field keeps getting deeper, broader, and more competitive.
The most important conclusion is that the best AI setup is no longer one model. It is the right rotation.
What should you use tomorrow?
Start with the task.
For backend engineering, terminal-heavy work, math, and technical problem-solving, I would start with GPT-5.5. For writing, design, frontend engineering, desktop navigation, and product-sensitive work, I would start with Claude Opus 4.8. When cost matters, I would look closely at Gemini 3.1 Pro. For high-volume agent workflows, I would bring Grok 4.3, Kimi K2.6, and DeepSeek v4 Flash into the rotation.
And when the task really matters, do not force yourself to pick only one model. Ask GPT-5.5. Ask Opus 4.8. Compare the answers. Let one critique the other. The frontier is now rich enough that using multiple models is often the smarter default.
That is the practical takeaway from May: the best model choice depends on the work in front of you. Use the charts, test the models against your own workflows, and build a rotation that gives you the most intelligence for the task, budget, and level of risk.
Help shape where AI IQ goes next
I’m going to keep adding benchmarks to AI IQ where they make the model map better: coding, reasoning, reliability, EQ, computer use, cost efficiency, and agentic performance.
But the bigger question is not just what AI IQ should measure. It is what AI IQ should help you do.
What would make AI IQ useful enough to become part of your actual model-selection workflow? Would you want personalized model recommendations, a routing guide by profession, a model picker for specific tasks, a browser extension, a team dashboard, cost-aware model routing, or a way to compare your own outputs across models?
That is the feedback I would most like to hear.
AI IQ started as a way to make sense of model intelligence. The opportunity now is to help people and teams use the right intelligence at the right time.
And that is where I’d love your help: what should AI IQ become next?
I like how your voice came through in this research. Great writing. And useful to think through when to use which models, and why. Thanks for writing this Ryan!